バッチ処理 プラクティス
SHARES
バッチ処理は既に先人の方々が多くのナレッジを公開してくれていますが、それでもなお難しさが変わらないテーマだと思っています。
この記事は、筆者がこれまでの開発経験で気づいたバッチ処理の実装ナレッジを整理し、体系化を目指して文章にしました。
ここでの内容が、より良い課題解決に貢献できれば幸いです。
自身の断片的な思考整理(メモ書き)の延長で内容を整理したため、一部書き振りが統一されておらず、読みにくいかもしれません。ご了承ください。🙏
バッチ処理の難しさ
バッチ処理は難しい。
人によっては簡単なテーマかもしれませんが、自分は難しいテーマだと思っています。
「難しさの根源は何か?」を考えると、1. 考慮点が多様にあること 2. 解決する課題によって答えが大きく変わること に整理できました。
この2点は、どのソフトウェア開発にも当てはまる項目ではありますが、ことバッチ処理においては顕著に現れます。
1. 考慮点が多様にあること
バッチ処理は考慮する点が多様にあります。
多量ではなく、多様としているのは考慮の幅が広く多角的だからです。
幸いにも考慮点は一般的なものとして整理されており、「何を考えて答えを出しておくべきか?」が定義されています。見てみましょう。
処理件数
- 処理を加えるデータ量はどれくらいか
処理時間
- 処理に必要な時間はどれくらいか
- いつから処理を始める必要があるのか
- いつまで処理を完了させる必要があるのか
回復性
- 容易に再実行が可能か
冪等性
- 同じ入力で何度実行しても同じ結果になるか
整合性
- 重複した処理でどう振る舞うか
- 処理の整合性は守られるか
- データの整合性は守られるか
可観測性
- 処理の進行状態を把握できるか
- 処理の完了状態を把握できるか
- 障害を検知し適切な行動を選択できるか
--
バッチ処理はこれらの考慮点に答えを出し、各方面との論理整合性を担保しながら、目的達成の手順を構築します。
主要な点を抑えながら仕様と考慮のバランスを取るのが難しい点であり、おもしろさでもあり、職人としての腕が問われる所でもあるでしょう。
2. 解決する課題によって答えが大きく変わること
バッチ処理には研究された答え(鉄板構成的なもの)がなく、またその表現は解決する課題によって大きく変わります。
「表現の振れ幅が大きいこと」「解決手段が無数に考えられること」が解決を難しくするところで。それはつまり「各々が前提の状況を把握した上で最適な表現を選択しなければいけない」ということです。
趣味で作った情報を集めて加工し保存するクローラーのバッチと、金銭が絡む高頻度で多量なトランザクションを複数コンポーネントに跨って扱うバッチでは、表現が全く異なります。
前者は仮に失敗しても損益を被る人がいませんが、後者は不利益が生じてしまう可能性があります。そのため、厳密なエラーハンドリングと、どこで問題が発生したのかが把握できる精密なログ出力を行い。さらに、リトライによる完全性の向上とロールバック機構で原子性が担保されているはずです。
これら後者の要件は前者に必須ではありません。しかし、「なんらかの形で必要だよね」といった温度感で、各要件にグラデーションを持たせて選択するのが一般的です。
もう言わずもがな、難しいことがわかると思います。同じバッチ処理なのに構造がまるで違う。。。
であるからこそ、バッチ処理の標準的な考慮点を洗い出せること、答えの模範を明らかにすること、そして場面に応じた適切な表現を選択できること、つまりはプラクティスを持つことは有益なことだと言えます。
考えることを減らしながら、一定の成果を出せる状態を作ることを標準化と言います。標準化を目指したバッチ処理の 守りたい要点 をここでは プラクティス と定義します。
プラクティス
先に抽象度の高い考え方的な話をしてきました。ここからはより具体的な実践内容を紹介します。 各項目に依存関係はないので、気になる箇所だけ目を通しても構いません。
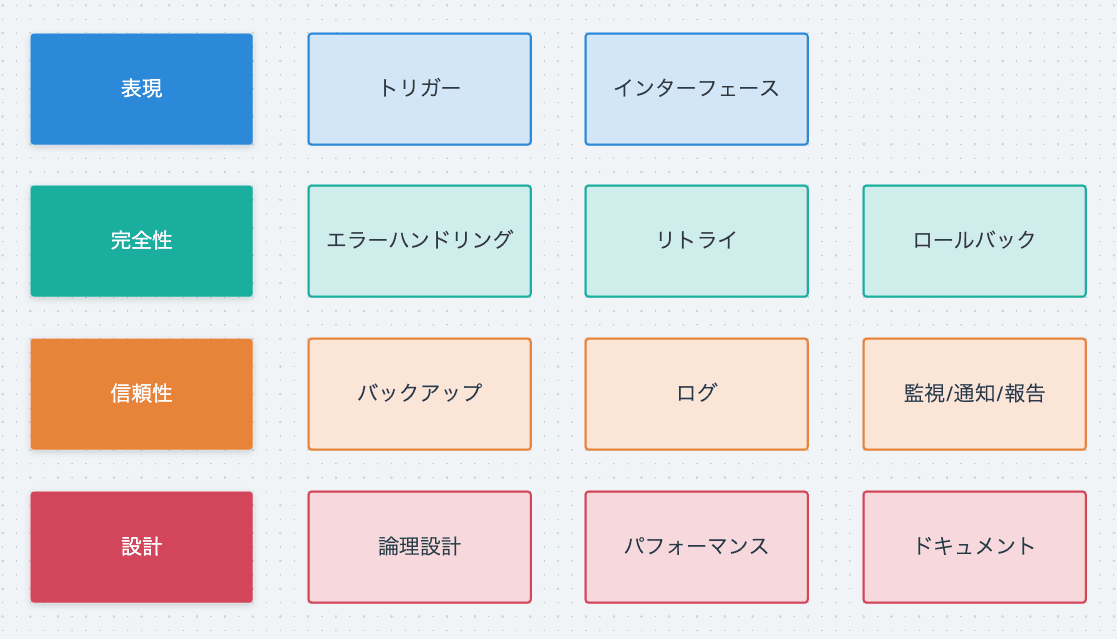
項目
- 論理設計
- トリガー
- インターフェース
- エラーハンドリング
- リトライ
- ロールバック
- バックアップ
- ログ
- 監視/通知/報告
- パフォーマンス
- ドキュメント
論理設計
まず大前提として、論理設計ができなければプログラムは書けません。
論理設計とは、不明確な期待を明らかにし、期待を達成するための技術要件を整理して、仕様を定義することです。
不明確な期待 → 論理設計 → 明確な期待(仕様) → 実装 → テスト → 期待の達成。
期待の不明確と明確の違いは、要求者と実装者の合意形成の有無です。
互いに (もしくは自分自身で) "こうあって欲しい" という願いを説明可能な状態にし、合意したものが明確な期待、つまりは仕様になります。
論理設計では、以下の8項目に対して説明可能な状態を目指します。
バッチ処理における、論理設計のステップ
- 処理で解決したいことは何か、なぜ解決したいのか (Why)
- インプットとアウトプットは何か (What)
- どれくらいの量のデータを扱うのか (How much)
- いつ実行したいのか、いつまでに完了したいのか (When)
- 前提条件、実行時制約、達成条件は何か (What)
- パフォーマンスの制約と期待は何か (What)
- 実行前と実行後にある業務は何か (What)
- 将来起きうる仕様変更と拡張は何か (When What)
項目全てを明らかにできれば、Howの選択肢が見えてくるはずです。
例えば、「パフォーマンスの制約が厳しいので並列化は必須」「実行完了を軸に次の業務を開始するため、エラーがあったら即座にやり直してほしい」「完了したかどうかのステータスを業務の人が確認できる状況を作る必要がある」など。
これらの制約があれば「並列化し、1分ほどで処理が完了できる様にする」「ステータスを確認できる状態を作る」「高い可用性を保つためのリトライ条件を設ける」といった具体要件に落とし込めます。
ここで選択した要件が仕様になります。
仮決めした仕様に自信が持てなければ、ヒアリングを重ねたり、逆に要件を提案しましょう。これを筆者は "論点整理" と呼んでいます。(詳しくは「仕様に対する振る舞い」を参照)
仕様が固まれば、あとは後述のプラクティスを盛り込みながら期待を達成する処理を作るだけです。
なお、達人プログラマーはいちいち論理設計で立ち止まったりはせず、手を動かしながら決めていったり、気付いた時点で修正を効かせられる柔軟性と余裕を持ち合わせてます。 最終的にはそういったレベルの立ち回りを目指したいです。
インターフェース
インターフェースを上手く設計できれば運用が楽になります。
インターフェース設計が解決すること
- 認知負荷の低減、理解の促進
- 手段の提示
- 単体テストのしやすさ
認知負荷の低減、理解の促進
バッチ処理は何らかの目的を達成するために作ります。そしてそれらは大抵が端的に表せるものです。
例えば、「ファイルをアップロードする」「ファイルをインポートする」「データを生成する」など。
これらの処理を端的に表す命名で作っていきましょう。
アップロードなら uploader 、インポートなら imorter 、生成なら generator 。 これで何をするのかがぱっと見でわかるようになります。
メソッドの表現は基本命名を execute に統一する様にしています。(個人の好み & 場合による)
トリガーに利用シーンがある場合は、 ByCron や ByWorker といった語尾を追加することもあります。
明快な命名や、統一された規則は認知負荷を下げ、初見での理解を促進する効果があるので、できれば統一したルールで運用するのが良いでしょう。
class ProductFileUploader {
// 基本の表現
Future<void> execute() async {}
// Cronで実行する処理
Future<void> exeucteByCron() async {}
// Workerで実行する処理
Future<void> executeByWorker() async {}
// コマンドで実行する処理 (検証用)
Future<void> executeByCommand() async {}
// 具体性を持たせた表現
Future<void> upload() async {}
Future<void> convert() async {}
Future<void> generate() async {}
}
手段の提示
インターフェースは時に手段を提示します。
この処理の呼び出しは何をサポートしているのか? どう振る舞うのか?を名前と引数から推察できる状態を作れると理解が捗ります。
引数の種別
- 対象範囲制約 (時間, データ条件)
- 処理制御 (ログ, 通知, フォースラン, ドライラン, アウトプットフォーマット)
class ProductFileGenerator {
Future<void> execute({
required DateTime targetDate, // 対象範囲制約
targetProductIds = const [], // 対象範囲制約
outputFormat = OutputFormat.csv, // 処理制御
bool skipDebugLog = false, // 処理制御
bool notify = true, // 処理制御
bool forceRun = false, // 処理制御
bool dryRun = true, // 処理制御
}) async {}
}
この例からは次のことがわかります。
- 日付を指定して実行する(デフォルト値がないため必ず要求される)
- アウトプットのパターンが存在しており、デフォルトがcsv (他の用途もカバーしている)
- targetが指定できるということは、特定のデータでのみ処理が行える (リカバリー系で使用すると推察)
- forceRunがあるので、何かしらを処理をスキップして実行できる
- skipDebugLogがデフォルトfalseなので、デバッグ時にのみ使う重厚なログ出力がある
- notifyがあるので、どこかに通知してる (通知するくらい重要なバッチなのだろうとも推察)
- dryRunがあるので、データを操作する前にprintができる (安全を考慮した確認ができる)
インターフェースは多くの機能情報を共有します。
「多すぎても逆にダメだ」という意見もありそうですが、重要で拡張性の高いバッチならこれくらいは普通にあるでしょう。
テスタビリティの向上
テストのしやすさもインターフェースで解決します。
execute のみで構成し、全てを1つのメソッドにまとめても良いですが、大抵はコード量に比例して処理が多くなり、見通しの悪化とテスト容易性 (テスタビリティ) の低下を招きます。
これを回避するために、凝集度を意識して分割することでコードに秩序をもたらし、ユニットテストの整備で客観的な安全性を保てる状態を目指しましょう。
インターフェースをどう切るか(何を軸に定義するか)は以下の資料が参考になります。 オブジェクト指向のその前に-凝集度と結合度/Coheision-Coupling
class ProductFileGenerator {
Future<void> execute() async {}
// 読み込み
Future<Shop> loadActiveShops(DateTime date) async {}
// 読み込み
Future<List<Product>> exportProductsByShop(Shop shop) async {}
// 加工・変換
List<List<Product>> selectAvailbaleProducts(List<Product> products) {}
// 加工・変換
List<String> purchaseProductRecords(List<Product> products) {}
// 加工・変換
Future<void> writeCsvFile(List<String> records) async {}
// 加工・変換
Future<void> writeTsvFile(List<String> records) async {}
// 出力
Future<void> uploadStorage(String filePath) async {}
// 出力
Future<void> sendSlackNotification(Result result) async {}
};
トリガー
使いやすさと安全性を兼ね備えたバッチトリガーは、運用を楽にします。
トリガー表現の考慮
- いつ/何をトリガーとするのか
- リトライのしやすさ
いつ/何をトリガーとするのか
- 特定の時間になったら実行する
- 特定のデータが存在したら実行する
- 特定の処理が完了したら実行する
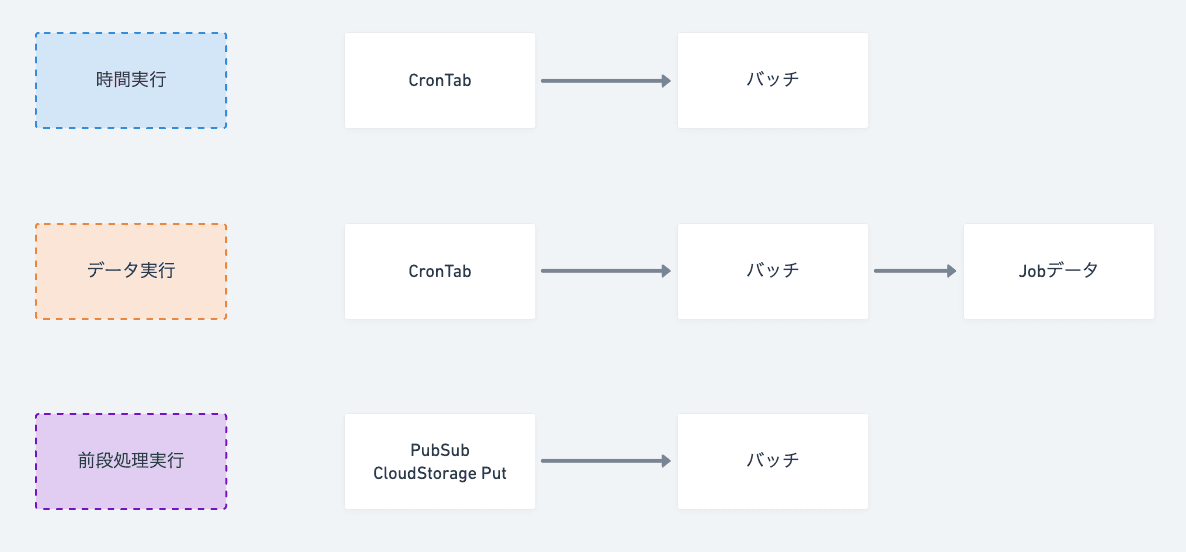
トリガーは要件によって決まります。経験的には、時間実行(6), データ実行(3), 前段処理実行(1) の比率でくる。
時間実行はCronTabの機能を使って実現するのが一般的で、Kubernetesを使っている場合はCronJobなどが使えます。
データ実行は、定期的にCronを実行し、該当データの有無によって実行を決定するケース。 ここでのデータはレコードのケースもあれば、ストレージのファイルなど様々考えられる。
実行に順序制約がある場合は、Jobデータを設けて、ステータスチェックで実行順序を制御する。
前段実行は、PubSubを挟んで、PublisherのメッセージをSubscriberが待つ構成や、Cloud StorageへのPutをトリガーとした構成で解決する。
個人的な鉄板構成を3つ出しましたが、トリガーは要件と運用を軸に考えられるので「一番楽な構成は何か?」という問いから逆算して最適な形を選択しましょう。
リトライ
何らかの問題で処理が失敗した場合、リトライ(再実行)を行うはずです。(詳細は後述)
トリガー観点では「リトライしやすいトリガー表現になっているかどうか」はケアしておきたいです。
これはリトライの方針に依存しますが、単純でわかりやすいリトライトリガーであればよく「失敗したJobを削除して、エラーを修正し、再実行ボタンを押すだけ」といった形が理想です。
エラーハンドリング
エラーを適切に対処するためのエラーハンドリング。
エラーハンドリングのパターン
- 1件でもエラーがあれば、処理全体を失敗とする
- エラーがあれば、該当処理をスキップして処理を続ける
- エラーの許容値を設けて、許容値内は続行、許容超過は失敗とする
絶対に失敗が許されない箇所であれば1になるはずです。仮に失敗しても問題なく、かつ他に影響を広げたくない場合は2になるでしょう。一定のエラーが発生しうる前提での処理は許容値で制御する場合は3を選択します。これらの制御は「エラーに遭遇した際、どうあってほしいのか?」という問いに答えると仕様を決めることができます。
この問いを元にエラー遭遇のシミュレーションを行うことをプレモーテムと呼びます。日本だと馴染みのない概念かもしれませんが、元メルカリのkoemuさんがプレモーテムに取り組まれていたり、最近だとPayPalのソフトウェア開発フローに組み込まれて成果が出ているという記事が出ていました。
このステップは非常に重要で、適切なエラーハンドリングを加える箇所の見極めに繋がります。 一人の視点だと漏れる可能性があったり、ハンドリングのより良い選択肢に気づけないこともあるので、できれば複数人に考慮のレビューをしてもらうのが良いでしょう。
レビュー担当
「この処理Aで失敗したら、どういう挙動をするの?」
実装者
「その場合は、該当のエラーが起きたデータを捕捉した後、後続には影響を広げないで処理を続行させます。」
「全ての対象データへの処理が完了したあと、エラー対象があればSlackに通知して気付ける状態にします。」
「こうする理由はバッチが処理するデータ量が膨大なので、1件失敗の影響が大きいとリカバリが大変になるからです。」
「エラーは滅多に起きない想定ですが、起きた場合にはリカバリを別のルートで行える時間猶予があるため、この設計にしています。」
こういったエラーケースを想定した仕様が組まれているかどうかを事前レビューでカバーすることで、実運用に載せた際の障害リスクの低減を目指します。
リトライ
処理の完全性を担保するためのリトライ。
リトライの設計にある側面
- バッチ処理自体のリトライ設計
- バッチ処理で利用する外部サービス連携でのリトライ設計
バッチ処理自体のリトライ設計
バッチ処理が何らかの理由で失敗した場合を想定して、リトライ機構を設けましょう。
リトライで一番考えることは冪等性。何度実行してもインプットが同じであれば、同じ結果になる処理が理想です。冪等性に拘る理由は、考えることが少なくなるからです。
冪等性に関しては、多くの良質な解説文献があるので、そちらを参考にしてください。参考:「リトライと冪等性のデザインパターン」
ちなみに、冪等性は性質なので、「その処理に冪等性持たせてる?」といった会話の問いで、同僚と仕様の確認をしたりしています。
また、常に0からリトライできる構造が理想です。
例えば、ファイルを生成するバッチの場合、途中で処理が失敗した場合、作りかけのファイルは破棄されて、リトライ時にはまた0からファイルを作り始める仕組みにし、失敗したファイルはリトライの考慮から外す仕様にしておく。 この場合、どこまで成功したのか、どこから失敗したのかという分岐が不要になるため、考えることが減り、失敗要因を解決して、再度実行することだけを考えれば良くなります。
バッチ処理で利用する外部サービス連携でのリトライ設計
外部サービスと連携したバッチ処理を作る場合、連携処理自体のリトライを考慮することも必要です。
外部サービス連携と呼んでいるものは、1.APIでデータを取得/更新するもの 2.クローラーでWebページからデータを取得するもの 3.サイトコントローラーで外部サイトを操作するもの などです。
これらの連携は成功する前提で処理を組みますが、失敗することを想定して、失敗した場合の期待動作と、成功に向かうためのリトライ処理を設けておきます。
APIリクエスト制御のリトライ方法は無数にありますが、言語ごとのデファクトスタンダードなパッケージを採用するのが良いかもしれません。もしくは自前で組むか。(ちなみに、Dartならretryがおすすめ)
リトライ処理自体が行うこと
- 失敗の識別
- リトライまでの遅延
- リトライの実行
- リトライの最大実行制御
上記の処理を外部サービス連携箇所に設けておきます。
さらに踏み込めば、エラー制御自体も合理的に組めていれば尚良いです。 "連携エラー" と言えど、1.呼び出し元起因のエラー 2.呼び出し先起因のエラー 3.介しているネットワークのエラー に分類できます。
リトライすべきは 2.呼び出し先エラー と 3.介しているネットワークエラー。 呼び出し元のエラーはリクエストが不正であることで、クライアント側 (つまりは自分たち側) の処理を直す必要があります。
適切なリトライ設計を施して運用対応が楽なバッチを目指しましょう。
ロールバック
0からやり直すためのロールバック。
ロールバックの種類
- 同期ロールバック
- 非同期ロールバック
同期ロールバック
同期ロールバックは実行中に問題が発生した場合に、データを実行前の状態に戻すことです。 戻した後に再実行するのか、またはスキップして続けるのかはハンドリングの設計方針で決まります。
ここでは 戻すこと だけを考えます。
"戻すこと" は 1.何に戻すのか(What) 2.いつ戻すのか(When) 3.どう戻すのか(How) に分解できます。
何に戻すのかは実行前の状態です。 戻す単位はエラー対象だけ、または対象を含む集合全てを戻す場合など。
いつ戻すのかは制御範囲でエラーが起きたタイミングです。 処理を3ステップ踏む場合、3つ目で失敗したら1と2でロールバックを行います。 仮にステップ2で失敗したら1のみのロールバックになります。
どう戻すかは処理形態に依存します。単に"戻す"といっても永続ストレージに備わっているトランザクション機能で要件を満たせるケースもあれば。API連携で結果整合になるケースもあります。
API連携の場合は、何に戻すのかを判断できるようにするために、実行前の状態を何らかの形式一時保存しておきましょう。これはメモリに持つケースもあれば、永続ストレージに持つケースもあります。
何か上手い図でも用意しようかとも思いましたが、世間には参考例がたくさんあるのでGoogle検索でイメージを掴むのが手軽そうでした。
非同期ロールバック
非同期ロールバックは完了後に、実行とは別プロセスで状態を戻すことです。
こちらはロールバック用のツールを設けておき、ロールバック用の処理として対応します。
非同期の場合、あらかじめ戻す状態のデータを保持しておく必要があるので、次項のバックアップと合わせて考える必要があります。あるべき状態を示すデータがあればツールを設けるだけなので、ロールバック自体の難しい考慮はないはずです。
ただし、ロールバックを行ってもデータや他の処理との論理整合性が担保できるのかどうかは、考慮が必要です。
バックアップ
事が起きてからの苦労を低減するためのバックアップ。
なぜバックアップを取るのか。(Why)
- リカバリー対応を楽にするため
- 不具合調査を楽にするため
- ロールバックに対応するため
どういった場合にバックアップを取るのか。(When)
- 一方通行な処理で、実行後に実行前の状態に戻しづらい場合
- アウトプット先が管理環境外で、調査と確認がしづらい場合
- 問題調査をログ出力や通知に頼るよりも、最終結果を確認した方が楽な場合
- リカバリーで作り直すよりも、1度作ったデータを使い回したい場合
- ロールバックで前の状態に戻す場合
どういった形でバックアップを取るのか。(How, What)
- BigQueryにテーブルを設けて、最終結果をレコード形式で保存しておく
- 最終結果と同じ内容のファイルをクラウドストレージに保存しておく
- JSON形式でローカルで一時保存しておく
- RDBにテーブルを設けて、レコード形式で保存しておく
Whenの項目に当てはまるなら、バックアップを取っておきましょう。
バックアップを無駄だと捉えることもできますが、無駄なのは半永久に保存しておく前提にあったりします。 それは本当に無駄かもしれないので、定期的(ex: 3ヶ月経過など)に保存したバックアップファイルをパージする(削除する)処理を挟めば合理的です。(= ライフサイクルの定義)
ログ
未来の運用者に向けたメッセージとしてのログ。
なぜログを出力するのか。(Why)
- 状況を把握するため
どういった場合にログを出力するのか。(When)
- 処理の開始と終了
- 処理対象の中身
- 処理の過程
- 処理のエラー
どういった形でログを出力するのか。(How, What)
いつ、何に対して、どうなったのかがわかれば良い。
'[start] WebArticleCrawler arguments: A, B, C' // 開始の出力
'[process] start execute 2021-11-23 12:00:31' // 時間の出力
'[process] crawl article for https://yamarkz.com/blog/aaaa' // 処理対象の出力
'[process] request params: { "category": "4", "page": "2" }' // 処理のインプット
'[process] response body: { list: [{"title": "hoge huga", "content"}] }' // 処理のアウトプット
'[error] catch execption error reason: 404 not found' // ステータスの出力
'[finish] WebArticleCrawler' // 終了の出力
出力対象はそれを見た時に適切なアクションが取れるかどうかを想像して選びましょう。
出力内容は具体的であればあるほど良く、引数やリクエストパラメータなどは鉄板の内容です。 組織内でログ出力のフォーマットを揃えるのも良いかもしれません。
監視/通知/報告
責任を果たすためにある監視と通知と報告。
なぜ監視/通知/報告をするのか。(Why)
- 状態に気づくため
どういった場合に監視/通知/報告するのか。(When)
- 例外を除いて基本全てのバッチで監視する
- 正常終了 or 異常終了 or 復旧完了した場合に通知する
- 月, 週, 日, 時の区切りで処理結果を報告する
どういった形で監視/通知/報告を設定するのか。(How, What)
- CloudMonitoring, Sentry, Grafanaなど監視手段は様々あり、ベターな選択肢を取る
- 通知と報告はコミュニケーションラインの大通りに流す
- 気づけないリスクは複数サービスの組み合わせや組織運営で解決する
監視/通知/報告の価値は初めは認識しづらい領域ですが、運用でしのぎを削った経験がある方は 「超重要である」 と言い切ってくれるはずです。
最初はどんな形でも良いので、監視と通知機構は設ける様にしましょう。運用に乗せると「こうあって欲しい」という点が見えてくるので、都度改善を行っていくのが良いです。
処理の完了状態監視はもちろん、定期運用レポートも安心安全なメンタルを作る上では必要です。
パフォーマンス
早い方が良いのがパフォーマンス。
完了時間短略化 (≒ パフォーマンス向上) を実現する手段
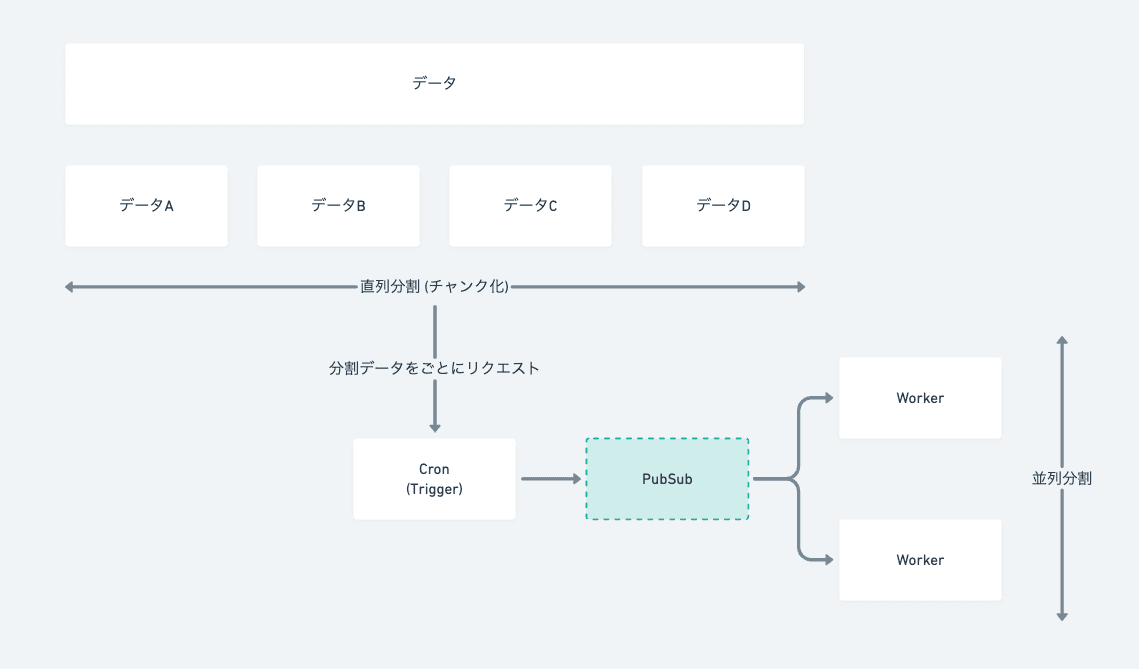
- 並列分割 (処理構造で解決)
- 直列分割 (データ構造で解決)
- リソースで解決 (お金で解決)
- チューニングで解決 (設定変更で解決)
並列分割 (処理構造で解決)
一定の基準で処理分割を行うことで、完了時間の短略化を目指します。
例えば、100店舗分の在庫データをチェックしてデータを更新する処理の場合、1店舗あたり20分かかるものを100店舗分実行すると 100*20 = 2000分 = 33時間かかってしまいます。データのライフサイクルが24時間で変わる場合、実行完了までに最遅で33時間かかる店舗はデータ更新が間に合わず、価値を提供できなくなります。
この問題に対処する場合、100店舗分の実行を並列で30店舗分ずつ実行すれば、100/30 = 3.3 * 20 = 66分 で完了に至れる様になります。
同期が約1時間で完了できる場合、深夜に実行すれば店舗の営業時間には十分間に合うので、要件を満たせそうです。
並列の仕方は言語により様々あるので、言語仕様に沿ったものを選択します。 (GoならGoroutine, DartならIsolate)
また、構成で解決する方法も考えられるので、要件によって適切な選択をします (図参照)
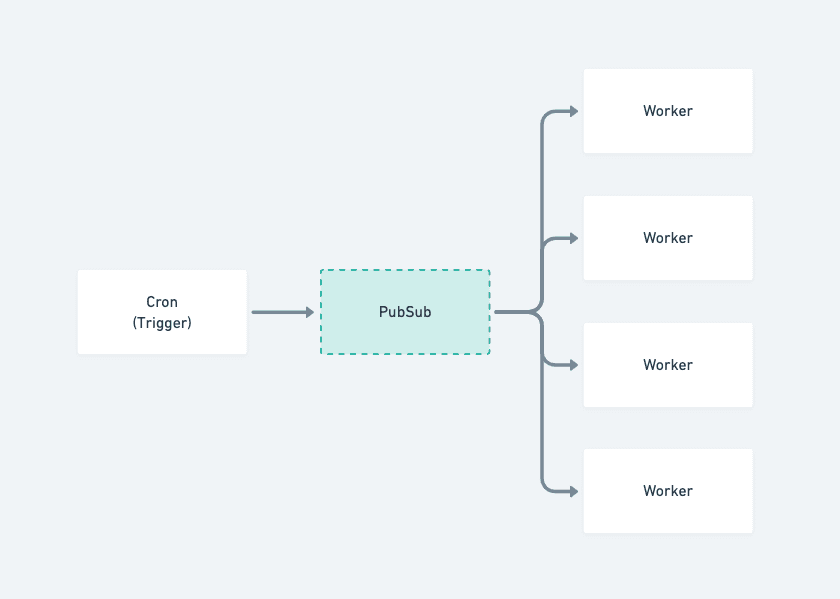
(CronとWorkerを分けて並列に処理する例)
直列分割 (データ構造で解決)
直列分割というのは個人的な名称で、一般的なものではないです。 並列処理との対比のイメージで直列に分割する様にも見えるため、そう呼んでいます。
処理するデータ自体が大きすぎる場合、並列で解決できないボトルネックがある場合などには処理するデータ自体を分割して完了までの時間を短くします。
例えば、1店舗の在庫同期でかなりシビアな完了時間の要件がある場合、在庫の中の同期処理単位をカテゴリーに分割して20カテゴリー分を並列で処理する形に変えます。
先の並列分割で店舗単位で並列化を行ったことでそれなりに早くなりましたが、さらにカテゴリーごとに分けることで完了までの時間を1/20近くに短くすることができます。
意識を実行処理ではなく、実行単位(データ)に向けて速度改善することが直列分割です。
リソースで解決 (お金で解決)
リソースで解決できることも考えます。これはマシンスペックのことです。
主にメモリなどはチープなものより存分に使えるものを用意して、並列数を増やしたり、常時実行可能な状態を用意してタイムラグを減らすといった選択肢をとり、パフォーマンスを改善します。
幸い筆者はリソースを理由にパフォーマンス要件を満たせないシビアな状況に遭遇したことがないのですが、今後ポケットマネーで運用するサーバーで高いパフォーマンス要件を必要となる場合には、慎重に検討したいです。
チューニングで解決 (設定変更で解決)
環境設定やセットアップ、処理の無駄が原因で遅くなることもあります。
一番わかりやすい例だと、RDBのテーブルに適切なインデックスを貼ることや、何度も同じデータを取りに行く処理にインメモリキャッシュを加えて、1度の問い合わせで完結させるなど。他にはデータの状態をチェックし、不必要に更新しないといったこともあります。
構造やリソースでの解決よりも、容易な変更で解決に至れる可能性もあるので、まずはチューニングで解決できないかも検討しましょう。
ドキュメント
最後にドキュメントです。
何をドキュメントにするのかは論争が起きやすいテーマですが、最低でも以下2つを設けておけば大抵のことはなんとかなります。ちなみに自分はドキュメント書けよ派です。
ドキュメントパターン
- デザインドキュメント
- 運用サポートガイド
デザインドキュメント
最初期の実装時に書くドキュメントです。 このドキュメントが最小の要件を満たす仕様を、自然言語で表すものになります。
初期デザインドキュメントを書くべき理由
- 初期実装での失敗を避けるため
- 将来の技術意思決定を助けるため
1は初期実装という最も自由な状態での開発に失敗するのを避ける狙いです。最も自由で実装が楽であるからこそ、拡張性を担保した構造と達成すべき品質が守られる構造にしておく責任があり、それを第三者の目(レビュー)を通して説明可能な状態にします。
2は技術的な意思決定を将来迫られた際の考慮漏れを防ぐ狙いです。初期だからこそ見えた考慮点があるはずで(運用に乗せたからこそ見えた考慮点の対比)、そういったものを自然言語で将来の意思決定者に伝えられる状態を作ることは、運用開発の速度向上と意思決定の精度向上に寄与します。
仕事上いくつかデザインドキュメントを書いたので、参考例として出したかったのですが、個人ブログ上に出せる内容の限界であったので、ここでの掲載を諦めました。別の機会に記事にして紹介します。
運用サポートガイド
文字通り、運用を助けるために書きます。ガイドがあれば運用体制のバトンを渡しやすくなり、人の冗長化も行いやすいです。
ガイドにするドキュメント
- リカバリー手段
- リリース手段
- 運用操作
リカバリー手段は先に書いたリカバリーを行う際の段取りを書きます。リカバリー自体をどの順序で行うのか、何に注意するのかなどを記載しておきます。
リリース手段は特殊な用件が絡んでいる場合に備えたものです。例えばリリース前に該当データを削除しておく必要があるなど。
運用操作は開発者以外の人が見て機能を使用する場合 (ex: プッシュ通知の配信) などに参照するものです。
ガイドドキュメント全体に言えることとして、ガイド内容はなるべく具体的であることに拘りましょう。「Aするだけで良い」「Bの値を書き換えてCを実行する」など。
最低でもこの2つがあれば、運用観点では100点でしょう。
初期デザインドキュメントは開発組織の文化や個人の力量に依存するものでもあるため、難しいかもしれませんが、書く文化になったほうが大規模開発では良いと個人的には思っています。
サポートガイドに関しては初期から設ける必要はなく、冗長化や規模が大きくなってきた場合や、責任範囲が広くなったタイミングで設けるのが良さそうです。
まとめ
バッチ処理は難しいが、考慮点と11のプラクティスを駆使すれば立ち向かえるはず。
最後に
バッチ処理について書いてきました。まだまだ書ききれてない観点もありますが、ひとまずアプリケーションエンジニアがバッチ処理に真正面から挑むための要点は抑えられたと思っています。
この文章を書きながら「考慮と設計はなぜやるのか?」という問いを考えていました。 自分の答えは「楽をすること」です。その心は、ソフトウェア事業は常に進化し続けるもので、進化への追従が競争優位になる特性を持っており、追従を楽にすることが競争力を生むことに直結するからです。進化とは、市場要求の変化と高度化、そして技術基盤の発展を指します。
優れた成果は、高い逆算思考から生み出されると考えています。 では、バッチ処理における逆算思考は何なのかというと、それは予防することです。
「仕様変更が来ても、バグを含めずに容易に拡張できる」「通信エラーが発生しても、リトライで完了に収束できる」「処理エラーが発生してもすぐに気づけて然るべき対処ができる」「データ量が増えても構造的に容易にスケールアウトできる」
これらの「できる」は全て予防から生まれます。(Not 対処療法)
「予防に勝る、運用なし」と言えるくらい、優れた設計ができる様になりたいですね。
Q&A
Q1. 妥当な選択肢が浮かばない場合、どうするのか
A. 調査&選定というステップを挟み、妥当性の高い選択肢をいくつかテーブルに挙げて検討を行います。メリデメや実現可能性、拡張性などを考慮した上で最良の選択肢を取ります。これ自体も一つの技術意思決定です。
Q2. 複数の処理をひとまとまりに行うバッチ処理での設計はどうするのか
A. 複数の処理を1つにまとめて処理を行います。特定のファイルを生成(Generator)し、指定の場所にアップロード(Uploader)するバッチ処理があり、それを確定業務と呼んだとします。その場合、確定バッチをFinalizerという命名で作り、FinalizerがGeneratorとUploaderに依存して、それぞれに処理を委譲する形で目的(ファイル生成とアップロードという確定業務)を達成します。
Q3. 意図的に逐次処理からバッチ処理を選択するケースはあるのか
A. あります。逐次処理ではレスポンスタイムに影響を及ぼす処理をWorkerに逃すという選択を取る場合や、強く完全性を担保したいシーンに結果整合性とリトライの組み合わせを取る場合が例として挙がります。
これらの場合、リクエスト側はポーリングやストリーミングなどで完了結果を待ちます。また、ユーザーとのコミュニケーションの設計も必要です。
Q4. どういった場合にロールバックを設けるのか
A. 2つあります。1. 論理整合性に価値があるデータに処理を加えなければいけないシーン。2. 実行後に整合性の担保が大変なシーン。どちらかに当てはまればロールバックは設けた方が良いです。
参考文献
この記事を書く以前から影響を受けた文献です。合わせて読んでみてください。
- バッチ処理の採用と設計を考えてみよう
- Web系の自分が想像と障害で学んだバッチ処理・設計の基本
- 続・Web系の自分が想像と障害で学んだバッチ処理・設計の基本
- リトライと冪等性のデザインパターン
- 続・リトライと冪等性のデザインパターン - リトライはいつ成功するか
- 続々・リトライと冪等性のデザインパターン - あらゆる操作を冪等にする方法
- Pre-Mortem: Working Backwards in Software Design
- 定期的に繰り返し実行する簡単ではないお仕事
- AWSにおけるバッチ処理の ベストプラクティス
- バッチアプリケーション設計のポイント
- 人に優しい定期バッチ処理を書く
- 安全なバッチ処理の作り方
- バッチ処理設計の考慮点
- バッチ処理における冪等性の検討
- オブジェクト指向のその前に-凝集度と結合度/Coheision-Coupling
- 「書く」のは特別な道具